





Your data,
your knowledge,
your advantage.

Data is business – a data strategy that is consistently thought through with this maxim in mind is far more than just a technical tool: the data strategy acts as a guard rail for data-driven decisions, paves the way for AI and analytics initiatives and forms the foundation of modern platform architectures. It also ensures data quality, establishes governance structures and strengthens resilience to market and regulatory dynamics. At the same time, it consolidates data streams, eliminates silos and promotes efficient, cross-company collaboration. This makes it a stabilizer in volatile times, an accelerator of decision-making processes and ROI and a strategic asset for sustainable innovation and the systematic use of knowledge.

The importance of data strategy consulting for digital transformation
Strategically developed and operationally accessible data forms the basis for well-founded decisions and serves as a catalyst for forward-looking innovation and growth. Those who adapt data-driven skills and technologies efficiently and in a company-specific manner proactively exploit opportunities.
A consistently implemented data strategy with company-wide governance and systematic metadata management forms the backbone of every compliance initiative. It guarantees the seamless fulfillment of requirements such as digital product passports, CSRD and other reporting guidelines – not only within your own company, but along the entire supply chain. At its core is a model-based data integration layer that collects relevant information centrally, updates it continuously and adapts it flexibly to new regulations. In this way, reporting tools are fed reliably and without additional manual effort, risks are minimized and the ability to react to changing requirements is accelerated.
The result: stress-free compliance, a significantly reduced risk profile and noticeably increased trust from customers, investors and supervisory authorities – a resilient basis for sustainable growth.
Modern data strategies bundle customer data from all channels – from online interactions to stationary purchases – in a central platform and thus create the basis for well-founded data analyses. Clear data management standardizes and controls all data flows, creating a reliable customer profile that precisely meets individual needs. Supplemented by sophisticated metadata management, semantic correlations become visible: behavioral patterns, preferences and interaction histories can be precisely recorded and interpreted.
On this solid foundation, customer experience solutions are created that go far beyond standard measures. Offers and communication strategies are automatically generated at the moment when they deliver the greatest added value. And because data is seamlessly exchanged between marketing, sales and customer service via a structured Need2Share concept, all areas benefit from the same, always up-to-date information base.
Finally, fine-grained data protection principles ensure that personal data is efficiently protected and at the same time remains available for authorized analyses.
An end-to-end data strategy that combines metadata management with semantic contextualization creates a central knowledge repository that is no longer dependent on individuals. All information – from tried and tested processes to many years of specialist knowledge – is recorded in a structured manner, documented in the right context and made usable across departments. Especially in times of demographic change, when experienced colleagues retire, this approach secures essential expertise and prevents knowledge loss. At the same time, semantic processing scales individual know-how, places it in an overall context and thus promotes interdisciplinary exchange and the creation of new insights – an indispensable basis for sustainable innovation and long-term corporate success.
A holistic data strategy that combines governance, metadata management and a need2share approach lays the foundation for powerful AI applications in the company. Only when all data sources are consistently standardized, semantically enriched and technically harmonized do models unfold their full potential: they provide accurate analyses, precise forecasts and create a reliable basis for strategic decisions. If this systematic framework is missing, there is a risk of fragmented information, error-prone evaluations and reliance on generic AI functions – a loss of competitive differentiation and efficiency.
At the same time, transparent data management with clearly defined roles, responsibilities and approval processes not only ensures secure compliance with regulatory requirements, but also strengthens cross-departmental collaboration. Relevant information is available in real time, innovations can be scaled more quickly and new business models emerge from the collaboration of all specialist areas. In this way, AI is not just a technical plaything, but a sustainable driver of efficiency, growth and long-term market leadership.
The comprehensive exchange of data along the supply chain is becoming a critical success factor: industry partnerships and regulatory requirements demand a consistent, error-free data pipeline that creates transparency and trust. A holistic data strategy defines shared data models and semantics, determines which information is required in which context and thus prevents misunderstandings and inconsistencies. Standardized formats – whether via APIs, streaming or clearly described data assets – ensure smooth data transfer between the respective IT systems and enable seamless process integration.
Another lever lies in the simple connection to cross-industry data rooms such as CatenaX or ManufacturingX in the Gaia-X ecosystem. Companies that have already established a structured framework for data administration and metadata management can use these platforms efficiently to exchange real-time data, intensify collaborations and jointly leverage new value creation potential.
A holistically anchored data strategy combines production data from all locations and system variants into a uniform information base. Clear responsibilities and binding quality standards ensure that all data – regardless of its origin – is processed consistently and reliably. Integrated metadata management gives the raw data semantic depth by placing machine parameters, location details and process variants in the right context. This foundation opens up AI use cases that go far beyond traditional predictive maintenance.
This means that maintenance requirements can not only be identified at an early stage, but also integrated directly into planned production windows. The result: synchronized control of maintenance cycles, production capacities and supply chain processes – the basis for scalable, company-wide decision-making systems. The result is a noticeable optimization of production planning and a more resilient supply chain.
This database provides the necessary speed and transparency for the automation of all business processes. In combination with modern process mining, processes can be analyzed in detail, bottlenecks identified and automation potential systematically leveraged. Redundancies are eliminated, resources are deployed with pinpoint accuracy and the organization gains agility. Overall, this interaction leads to considerable increases in efficiency, significant cost savings and a sustainable advantage in the globally networked production environment.
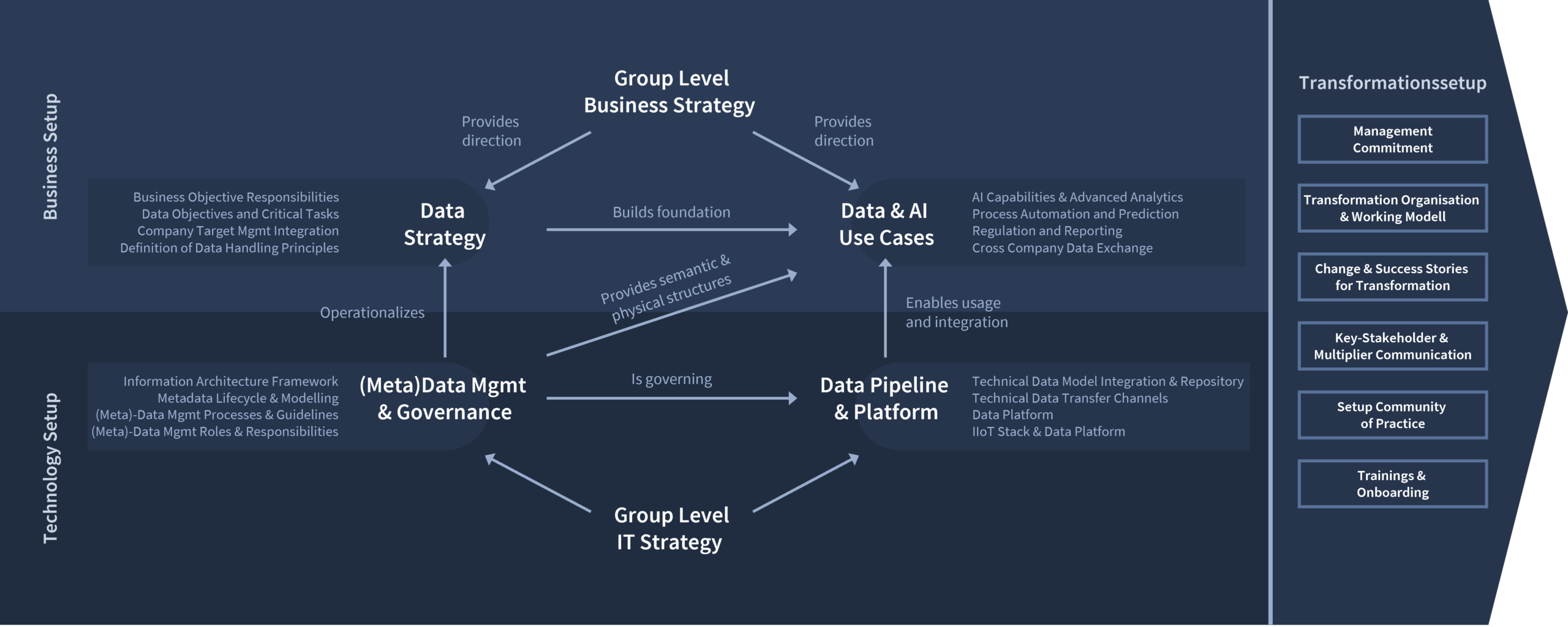
Central fields of action for implementing the data strategy
The realization of an effective data strategy is based on six central fields of action: Corporate and data strategy, use case development, governance structures, data pipelines and the transformation setup. The interaction of the individual fields of action creates a seamless and closely interlinked value chain:
Specialist departments derive a precise data roadmap from the corporate strategy and use it to develop use cases with clear, measurable business value. Metadata management and data governance lay the semantic and organizational foundation, while flexible platform architectures for data integration ensure performance and agility at a technical level.
Ventum Consulting orchestrates this end-to-end process to systematically increase data maturity. In this way, “data is business” becomes a living reality throughout the company and drives sustainable success.
A clearly defined business strategy not only defines growth paths, but also sets the guidelines for an effective data strategy. Data is not an isolated IT solution project, but an integral success factor: “Data is business”. Only when the specialist departments assume responsibility for content, objectives and roles does the data strategy become firmly established across all levels. In this way, data-driven projects gain the necessary acceptance and clout to create real added value in the long term.
As an operational blueprint for data-driven success, the data strategy translates the business strategy into clear data objectives and critical tasks. Embedded in target management, it defines measurable results – from AI insights to automated processes and reporting – as well as the roles responsible in each case. Binding data handling principles guarantee the consistent collection, processing and transfer of all data. This creates end-to-end transparency about where data creates added value, who provides it and what standards are applied throughout the company. This orchestrated interaction gives the data strategy the necessary power to turn data into a driver of growth and innovation.
Data & AI use cases that create real added business value can be derived from a well thought-out data strategy: AI and advanced analytics solutions uncover hidden correlations, process automation & prediction eliminates manual routine activities and delivers precise planning forecasts. A structured regulation & reporting approach automates management reports and ensures that all compliance requirements are met. Last but not least, cross-company data exchanges with clearly defined access and security rules open up completely new cooperation models with partners and suppliers.
Reliable metadata management and stringent data governance are the prerequisites for reliable use cases. An information architecture framework defines the structure and lifecycle of the data models as well as the creation and updating of all metadata. Clear, documented data management processes and guidelines supplement this with binding workflows, while clearly assigned roles – from data steward to data owner to data engineer – define responsibilities. This not only creates a common “data language”, but also a solid basis for quality, transparency and complete traceability of all data flows.
Finally, the technological building block is the Data Integration Platform, which enables the technical implementation of the use cases. Modern setups store and orchestrate large volumes of data and focus on model-based integration and processing of a wide variety of sources. Data transfer channels – from streaming APIs to AI agents – guarantee that information is provided in real time or at defined intervals for specific applications. The setup in manufacturing companies as well as plant providers and operators is supplemented by IIoT stacks and edge platforms that collect sensor data and feed it into the central data landscape. Together, these infrastructures ensure that all use cases can be operated in a high-performance, secure and scalable manner.
Between digital leadership, business and IT, the right transformation setup determines the success of a data-driven enterprise. Architecture, use cases, metadata management and platforms only unfold their full potential in an integrated framework:
- Management commitment
Clear targets, sufficient budget and visible support at top management level create the framework for all further steps. - Transformation organization & operating model
Clear roles and responsibilities across specialist and IT silos ensure smooth processes and accelerate decision-making. - Change management & communication
Targeted reduction of resistance, promotion of digital leadership skills and active stakeholder engagement ensure the acceptance of employees throughout the company. - Community of practice & upskilling
Continuous knowledge sharing, best practice formats and structured training and onboarding programs promote skills development and anchor data-driven methods in the long term.
Data strategy - maturity assessment
Step-by-step implementation of your data strategy

Our three-phase data strategy maturity assessment records your current status, uncovers potential for optimization and provides a clear action plan instead of mere classifications. The phases are aligned with your use cases and can be used as a benchmark for new and completed projects.
The holistic analysis of all core components – from data governance, metadata management and Need2Share through to data pipelines – results in an objective assessment of your data management. With the actionable recommendations derived from this, you receive a structured roadmap with which you can raise your use case portfolio and transformation program to a higher level of maturity, scale it and develop it sustainably. Understand where you stand. Know what to do.
With our maturity level assessment, you go through a clearly structured process in three steps.
The lever for the leap
to the next maturity level
Level 01
Explore & Evaluate
In stage 1, all scenarios run as isolated PoCs – manually complex and technically limited. They are suitable for quickly gaining knowledge, but do not achieve the necessary depth for productive operation. Only clear governance, systematic metadata management, Need2Share mechanisms and automated pipelines create a scalable basis.
- Compliance and regulation
Can be implemented: Manual recording of relevant key figures (e.g. CO₂ values or product passports) via CSV export and Excel reporting.
Limitations: No automated data line, low auditability and high risk of error in the event of regulatory changes. - Customer experience and customer data protection
Can be implemented: manual segmentation of customer lists in Excel, sending of static mailings.
Limitations: no dynamic profiles, no fine-grained data protection, separate silos between marketing and service. - Data as a knowledge repository
Can be implemented: Individual experts document findings locally in documents or Excel.
Limitations: No central findability, lack of semantic networking, high maintenance effort and loss of knowledge when personnel change. - AI applications
Can be implemented: Use of existing “off-the-shelf” AI solutions to support manual work and offline training of simple models on small, manually aggregated data sets (e.g. vibration values for predictive maintenance).
Limitations: Inconsistent data quality, no semantic context, not reproducible and hardly scalable to other systems or use cases. - Production data & integrated AI use cases
Can be implemented: Load local sensor values read by hand as CSV into a PoC tool and evaluate them manually.
Limitations: No comprehensive view of locations/plant variants, no real-time streaming and no process or supply chain orchestration. - Cross-company collaboration
Can be implemented: coordination by e-mail with partners, manual sending of files or dedicated implementation via local interfaces.
Limitations: lack of standard formats, no common understanding of data, time-consuming and error-prone. - Operational efficiency and automation
Can be implemented: Basic process mapping via interviews, evaluation of log files in Excel.
Limitations: No real-time transparency, no automation, lack of integration with Celonis or other mining tools.
- Compliance and regulation
Conclusion: Level 1 is ideal for gaining initial experience and roughly outlining use cases. However, structured data governance, metadata management, Need2Sahre mechanisms and automated data pipelines are required for the productive operation and scaling of all the scenarios described.

Transition:
Level 1 to Level 2
The transition marks the step from isolated prototype data experiments to the first viable minimal viable products (MVPs) and initial productive data use cases.
Key tasks:
- Define and anchor responsibility model
Set up a responsibility scheme based on current practice and clearly document who is responsible for decisions, quality assurance and escalations for each data object. - Formalize policies and processes
Develop binding guidelines on data quality, compliance and data protection and integrate them into your standard workflows (e.g. change requests, ticket systems) to ensure consistent implementation. - Implement monitoring and audit capabilities
Create dashboards for real-time monitoring of data quality and compliance metrics, automate regular audit reports and inform those responsible in the event of deviations. - Carry out change management and training
Conduct practice-oriented training for all stakeholders and employees, establish a continuous review and lessons learned cycle and continuously adapt guidelines based on pilot experiences.
- Set up use case metadata catalog
Implement a dedicated catalog for the use cases to describe metadata and link it to processes and IT systems. - Define taxonomy and glossary
Work closely with the specialist departments to identify key business terms and data classes and record them as business objects in a glossary. - Integrate metadata templates into pipelines
Anchor standardized templates for field descriptions, origin information and quality indicators in the existing ETL jobs or integration scripts of the use cases. - Practical implementation of semantic annotation
Define rules on how physical data elements are linked to business objects (e.g. measuring point, system, business object) and document them directly in the catalog. - Start review and maintenance processes
Designate a data steward for each use case who regularly checks metadata for completeness and up-to-dateness and makes adjustments. Anchor this procedure in the data governance. - Training the pilot teams
Conduct compact workshops in which developers and business users learn how to record and use metadata correctly and apply the central templates.
- Define use case-related sharing guidelines
For each use case, define which data is only available on the basis of a dedicated access reason (“Need to Know”) and which data is freely accessible company-wide or for specific areas (“Need to Share”). - Implement an approval workflow
Set up a standardized approval process (e.g. via ticket system or email template) in which those responsible for the respective use case check and approve data requests. - Clearly formulate data offerings
Use the metadata to “showcase” available datasets in a transparent and user-friendly way and thus enable easy access for all users. - Provide training and documentation
Train pilot teams in the approval workflow and how to use the data directory, and create short how-to guides so that the process is applied uniformly by everyone involved.
- Define use case scope and data sources
For each use case, define which systems or sensors are to be connected, which formats and frequencies are required, and record these in an architecture overview with a link to the semantic metadata. - Replace manual exports with ETL jobs
Replace ad-hoc CSV exports with automated scripts or simple workflow tools that extract and load data regularly. - Set up connectors and APIs
Implement IoT gateways, REST API clients or database connectors for each use case to reliably connect source systems to your pipeline. - Standardize data preparation and transformation
Develop reusable transformation modules in your ETL jobs and parameterize them for different data schemas. - Configure basic orchestration and scheduling
Use a lightweight orchestration tool or a scheduler to trigger ETL jobs on a time-controlled basis and to map dependencies (e.g. between extraction and loading). - Ensure logging, monitoring and error handling
Set up centralized log files, automated alerts and retry mechanisms so that pipeline errors can be detected and rectified at an early stage. - Establish documentation and deployment pipelines
Maintain brief, versioned documentation of your pipeline configurations and set up CI/CD pipelines to transfer changes to the pilot environment in a controlled manner.
- Strengthen digital leadership
Identify capability gaps and develop a modern leadership concept with clear roles and responsibilities for successful corporate management in the digital age. - Communicate data vision and strategy
Develop a clear, company-wide message that explains the benefits of data-driven processes and place it in leadership meetings and internal communication channels. Refer to use cases that already exist or are currently being implemented and show how they contribute to the data strategy. - Secure executive sponsorship
Ensure that C-level or management and division heads act as advocates, define binding targets for use cases and approve budgets for data initiatives. - Establish data champions and cross-functional teams
Appoint “data champions” who act as multipliers and form cross-functional working groups for exchange and collaboration. - Promote data literacy and awareness
Conduct target group-specific workshops and training courses to impart basic knowledge of data, tools and methods and raise awareness of data-driven value creation. - Introduce incentives and performance measurement
Anchor data strategy-related KPIs in target agreements and reward successes from projects to increase motivation and acceptance. - Build change agents and community
Establish a network of committed stakeholders who regularly share lessons learned, document best practices, promote innovation and actively support employees when hurdles arise. - Anchoring innovation hubs
Establish targeted formats for the further development and promotion of a future-proof, data-driven company.
- Build an enterprise architecture blueprint
Start by defining data, application and infrastructure models in an architecture repository. Establish uniform levels, viewpoints and artifact templates. Ensure that all new use cases are based on this conceptual foundation in order to promote reuse and consistency. - Define and operationalize the process model
Establish a lightweight, iterative framework that brings together business and IT areas on a team basis and defines clear roles and artefacts (backlog, user stories, acceptance criteria). Regular review cycles of your use cases enable fast correction and feedback loops. - Provide method templates and best practices
Develop standardized templates and checklists for the rollout of data management, metadata maintenance, pipeline automation and release workflows. Make these artefacts available to all project teams and integrate them into your organization’s existing or emerging architecture approach. - Implement lessons learned process
Carry out a structured retrospective after each pilot, document successes and challenges and transfer lessons learned to the next round of the project. Share the key findings across the organization. - Offer training, coaching and mentoring
Offer targeted training on data strategy, metadata management and pipeline orchestration. Establish an internal network of experts (“data coaches”) who support pilot teams in methodological and technical issues.
Ready for the next step?
The next step is to set up the first formal structures, processes and tools that will enable the scalable piloting of data-driven applications.
Level 02
Piloting & learning
In stage 2, initial added value is created – semi-automated reports, specialized AI models, data products and API pilots. For seamless scaling and transfer to other use cases, however, there is a lack of uniform company-wide governance, semantic metadata management, automated pipelines and a central Need2Share system.
- Compliance and regulation
Implementable: For defined areas, key figures (e.g. CO₂ emissions, product passports) are automatically extracted from the core systems using ETL jobs. Data owners define standardized validation rules, metadata describes data sources and purposes. This creates semi-automated reports that can be used regularly for internal or regulatory purposes.
Limitation: The automated pipelines and approval processes only apply to selected use cases – for new reporting obligations or additional domains, dedicated adaptations and CSV exports are still required, which must be developed specifically from a conceptual and technical perspective. - Customer experience and customer data protection
Implementable: Customer data from dedicated channels is fed into a cloud database, semantically enriched and used in a BI sandbox for personalized campaigns. Those responsible for the use cases define fine-grained data protection rules that are taken into account during segmentation and playout.
Limitation: The implementation only applies to selected marketing or service use cases. A holistic customer data platform setup with company-wide role and rights management as well as the corresponding semantic description is still missing. - Data as a store of knowledge
Implementable: The first “data products” or “data assets” are cataloged and the underlying know-how is summarized via metadata glossaries, modeling and taxonomies. The semantic description of data, or rather business objects, enables quick access and understanding of content – regardless of the availability of experts.
Limitation: The knowledge network so far only covers the defined use cases and, due to the lack of a company-wide ontology, access to content is not yet available across the board. Company-wide networking and comprehensive knowledge graphs have not yet been established. In addition, semantic knowledge is often not linked to the physical data models and source systems. - AI applications
Implementable: The relevant data records are loaded, processed and aggregated from the source systems via technical interfaces. On this basis, ML models can be trained on consistently pre-validated data (e.g. predictive maintenance for defined plant variants) or provided as input and context for existing models – keyword: “semantic prompting”. Metadata documents model parameters and data origin, allowing algorithms and knowledge specific to the use case to be used.
Limitation: Quality assurance rules and semantic contexts only exist in the use cases and are not accessible and understandable across the board. Scaling to other use cases or extending to other business areas requires additional manual effort and local metadata extensions. In addition, the use cases are usually isolated and only map certain functional areas. - Production data & integrated AI use cases
Implementable: Dedicated pipelines transmit sensor data from systems via data assets or streaming services. This gives technicians standardized access to functions such as predictive maintenance or production planning support.
Limitation: The orchestration of the individual use cases still requires active control by technicians or corresponding experts. The use cases are not or only slightly connected in terms of content. Locations or system variants must be dedicated and added individually. Company-wide process and supply chain orchestration does not yet exist. - Cross Company Collaboration
Implementable: standardized data formats (e.g. IoT measured values or product master data) are exchanged for defined use cases via API interfaces with partners. Approvals follow the Need2Know principle: every data transfer is checked on a case-by-case basis and approved via defined workflows.
Limitation: Only selected partners and use cases are connected. The central platform and company-wide release management are missing for other supply chain scenarios. - Operational efficiency and automation
Implementable: Log data from selected core processes is automatically fed into the process mining platform via an ETL job. Initial process mining analyses show bottlenecks and provide fields of action for pilot automations (e.g. workflow triggers for approval processes).
Limitation: Process Mining integration is limited to individual process domains and does not run in real time. End-to-end automation and company-wide monitoring have not yet been implemented.

Transition:
Level 2 to Level 3
The transition means transforming successful MVP projects and isolated use cases into a company-wide, end-to-end and largely tool-based data management framework.
Key tasks:
Set up an enterprise data governance framework
Define a cross-platform framework with uniform principles for processes, roles, guidelines and tools – based on a standardized reference model instead of local isolated solutions. Involve data suppliers and users alike and ensure that all steps of data value creation are covered, from strategic planning to the delivery of the payload.Harmonize role and responsibility model
Standardize data roles such as data steward and data architect in all areas, document responsibilities in a central RACI schema and anchor these in job and service level agreements.Translate strategic data requirements into a use case roadmap
Conduct workshops with data suppliers and users to translate strategic requirements into concrete use cases and operational data specifications and embed them in your governance framework in a prioritized manner.Establish user-oriented data governance
Define data governance steps based on implementation-oriented usage scenarios and user journeys for data consumers and suppliers and link these to your use cases in the overarching framework.Strengthen the governance community and change management
Set up a cross-divisional Data Governance Council, promote regular exchange formats and lessons-learned reviews in order to iteratively adapt guidelines and anchor a data-driven culture in the long term.
Set up a central metadata repository
Consolidate use case lexicons in a cross-platform catalog and link data products, pipelines and business objects semantically. Involve data suppliers and users in workshops to jointly define terminology and dependencies. Develop a company-wide ontology and taxonomy and anchor maintenance and further development in the data governance framework.Implement an automated metadata pipeline
Establish pipelines that transfer semantic changes directly into physical schemas with the help of tools and apply them to streaming services or data assets as required. Set up schema mapping monitoring to detect gaps between the semantic and physical model so that you can react promptly to the need for adjustments.Ensure integration into the data management framework
Link the metadata repository with your governance tooling and data pipelines so that metadata workflows are seamlessly embedded in service management and automation processes.Implement enablement and change management
Conduct target group-specific training for data stewards, developers and business users to teach them how to use the repository, ontology and governance workflows. Supplement this with communication plans and stakeholder engagement to promote acceptance and ensure continuous improvement.
- Introduce an enterprise self-service portal
Implement a central platform (data catalog/data mesh) as a single point of access for all data products and ensure cross-departmental access via an intuitive interface and standardized processes. - Define and publish a data product pool
Identify and catalog recurring data services (e.g. master data, sensor data, KPI sets) as independent data products. Define clear service level agreements (availability, throughput, latency) and publish these in the self-service portal. Use the taxonomy developed from metadata management as a basis. - Automate access concepts and policy enforcement
Harmonize role-based access rights while defining external “need to know” rules for partners and regulatory requirements. Use automated gateways that validate and approve access requests – without any manual intervention. - Clearly regulate “need to know” vs. “need to share”
Work with data providers and users to develop a tiered catalog that clearly separates internal sharing scenarios (“need to share”) and external approvals (“need to know”). Anchor these rules in the governance framework and in the governance tools. Link classifications semantically and physically with the metadata catalog in order to establish use case by use case dedicated pools of “need to share” data – efficiently and securely from a regulatory perspective. - Establish monitoring, usage analytics and auditing
Set up dashboards that visualize usage statistics (who accesses which data products and when?) and generate automated reports for compliance, quality assurance and resource allocation. Define alerts for unusual access patterns and other actionable events. - Implement change and enablement measures
Train specialist departments and partners in the use of the self-service portal, communicate the new sharing guidelines and offer hands-on workshops. Increase acceptance through regular success stories and best-practice presentations in the Governance Council and explain regulatory requirements and risks to data controllers together with data protection and risk management.
- Introduce an orchestration framework
Evaluate and implement a central platform for controlling all batch and streaming pipelines. Define a reusable architecture pattern including standard templates for common data flows. - Implement infrastructure-as-code and CI/CD
Anchor pipeline definitions as code in a version repository. Set up automated tests and deployment pipelines to transfer changes to development, test and production environments in a controlled manner. - Standardize uniform connectors and data adapters
Use modular, reusable connectors for source systems and integrate batch and real-time connections in a consistent framework. - Establish monitoring, logging and SLA reporting
Implement a central observability dashboard that visualizes the throughput, latency and error rates of all pipelines. Automate alerts and SLA reports to inform those responsible immediately in the event of deviations. - Automated error handling and recovery workflows
Implement retry mechanisms, dead letter queues and back-off strategies. Define clear escalation and recovery processes that take effect automatically and notify data stewards as required. - Change management and enablement
Train data engineering teams in the new orchestration and IaC tools. Maintain a central library of pipeline templates, best practices and lessons learned for rapid knowledge transfer and continuous improvement.
- Establish “Data is Business” as a fundamental principle
Establish the data strategy as a clear and central component of the business. Give the specialist departments a dedicated leadership role in this transformation and shape the departments’ sense of responsibility and understanding for their data. Establishexecutive sponsorship and data-driven targets
Gain C-level and divisional managers as active advocates, anchor the data strategy in the overarching business objectives and cascade the objectives to all organizational levels. Define and communicate company-wide KPIs to measure progress.Promote data competence and data literacy
Launch tailored training programs for managers, specialist departments and IT teams to impart basic knowledge of data, analysis methods and tools and create a common language. Focus on implementation benefits in the current working environment.Establish data champions and cross-departmental communities
Appoint data champions in each department who share best practices, provide impetus for innovation and act as bridge builders between departments. Integrate IT departments as equal partners in this exchange.Implement a communication setup
Establish a continuous communication plan with town hall meetings, newsletters and success stories to transparently present successes, learnings and milestones and to sustainably strengthen acceptance of your data management framework.
- Integrate the data governance framework into operational processes
Derive specific working models from the framework and anchor them in your (agile) development processes. Link the data and information architecture with the practical implementation steps and include all other architecture levels – from processes and applications to technology development. - Establish an enterprise architecture blueprint
Set up a central architecture repository that contains conceptual models for data, application and infrastructure layers. Use this “single source of truth” for all new data use cases to ensure reusability, consistency and compliance. Organize the architecture layers either centrally or integrate specialized tools via suitable interfaces. - Provide templates, checklists and best practices
Create a library of method templates and architecture reference models and make them accessible to all teams – this prevents isolated solutions and shortens the time-to-value of new projects.
Ready for the next step?
The next step requires a strategic expansion of the governance framework, metadata ontology, data ops methodology as well as leadership and culture that actively drive data-driven scaling.
Level 03
Scale & automate
In the third stage, use cases such as real-time compliance, predictive maintenance or live personalization run fully automated, highly scalable and AI-supported. Orchestrated data pipelines, robust control structures and adaptive metadata workflows ensure that end-to-end processes adapt seamlessly to new regulatory requirements, technological innovations and growing business domains.
- Compliance and regulation
All relevant key figures – from the digital product passport to CSRD metrics – are aggregated in real time via orchestrated data pipelines and made available in central dashboards for specialist departments and regulators. Data quality and data protection guidelines are firmly anchored in the governance toolchain so that automated workflows immediately trigger audits and corrective measures in the event of deviations. Metadata-driven schema updates can be seamlessly supplemented by the specialist departments, enabling a permanent improvement and adjustment process. - Customer Experience and Customer Data Protection
Live personalization across all channels: customer profiles are updated in real time, AI bots play out context-appropriate offers and all transactions run under fine-grained consent rules of data governance. Metadata automatically regulates the visibility of attributes, and an integrated privacy engine service ensures GDPR-compliant documentation. In-store analytics and IoT device data will be integrated in future and automated privacy impact assessments will be started. - Data as a knowledge repository
A company-wide metadata catalog with ontology and knowledge graph makes all business objects – from machines and processes to customer profiles – accessible via self-service. Experts publish data products with contextual semantics that flow into physical data schemas. Integrated governance workflows continuously develop the ontology; AI-supported extractors will also connect unstructured sources such as documents or emails. - AI applications
Sensor data, process and service logs are continuously fed in via streaming services. Semantic-prompting parameters from the Enterprise Knowledge Graph contextualize the inputs so that processing and output are company-specific. Retraining cycles are established and integrated model monitoring monitors drift and bias. In the future, the integration of external benchmark data will further increase the accuracy of predictions and the robustness of the model. - Production data & integrated AI use cases
Automated streaming pipelines transport live sensor data from all locations and system variants to central analytics and AI environments. Predictive maintenance algorithms, production planning heuristics and supply chain control are linked in orchestrated workflows so that maintenance windows are automatically booked and replenishment processes are initiated. - Cross-company collaboration
With seamlessly integrated APIs and a data mesh architecture, the company is fully operational in data rooms such as CatenaX. Access and approvals are automated, standard formats and security policies are maintained based on metadata. End-to-end processes such as the real-time tracking of components across partner boundaries run without manual intermediate steps. Future self-service onboarding templates will enable new partners to be added dynamically. - Operational efficiency and automation
All core processes are fed into the process mining framework via event streaming. Live analyses uncover deviations, rule-based triggers immediately activate RPA bots or microservices to control workflow dependencies. Process Variant Discovery is used to continuously identify new automation potential, and domains such as HR or finance are successively integrated into central monitoring.
Kick-start to a data-driven company - your basis for AI, data-driven use cases & knowledge management
Turn raw data into tangible value: with our tried-and-tested kick-start program, you can lay the foundations for sustainable, data-driven transformation in just a few weeks.
- Individual structural framework with integrated use case blueprint
- Quick project start thanks to preliminary analysis, tried-and-tested templates and best practices
- Uniform integration approach for synergies and scalable modules
- Precise gap analysis for immediate skills and resource development
In line with the principle of “think big, start small”, we rely on a tried-and-tested toolbox of methods and practice-oriented expertise: together, we develop a tailored structural framework, test it with a focused pilot use case and transfer the insights gained to your strategic data initiatives. This creates a resilient framework for designing and planning your most important areas of transformation – efficiently, iteratively and with guaranteed impact.
Your contact person

Also discover our Data Workshops
Data Role Workshop
Find out how your company can achieve clearly defined data roles, unambiguous responsibilities and robust data governance in just a few days – practically structured, organizationally anchored and usable as a sound decision-making basis for strategy, collaboration and data-driven transformation.
Semantic Data Modeling Workshop
Find out how your company can develop a viable, technically clean information model in just one day – clearly structured, business-oriented and immediately usable as a basis for analytics, AI and better decisions. You will gain transparency about data flows, responsibilities and quality, bundle knowledge from heads in a reusable model and thus create the basis for scalable, reliable and accelerated data-driven implementation.
Data Use Case Workshop
Learn how your company can identify the most relevant data and AI use cases, assess their benefits, feasibility and risks and derive a clear, prioritized roadmap in just one day. You will gain transparency about information contexts, data quality and dependencies and create a reliable basis for decision-making that consistently brings together strategy, business and implementation – for faster results instead of endless discussions.
Related articles










Arrange a non-binding initial consultation now
- Future-oriented: Targeted use of potential as a growth driver
- Tailor-made: Individual solutions for your specific challenges
- Tried and tested: 20 years of practical experience from successful projects guarantees reliability
- Strong implementation: from conception to measurable realization of results
- Value-oriented: Clear focus on sustainable benefits and real competitive advantages

TISAX and ISO certification for the Munich site only
Your message
Frequently asked questions about data strategy consulting
A data strategy defines how a company systematically collects, manages and uses data to create added business value. It defines standards for quality, security and governance and promotes data-based decisions. The aim is to support transparency, efficiency and innovation in a data-driven way.
Data is a key resource for competitiveness, innovation and operational excellence. A clear data strategy is the basis for making targeted use of potential and minimizing risks – especially in times of AI, growing data volumes and regulatory requirements.
The basis of a data strategy is the analysis of the existing data landscape and a close alignment with the business objectives. Clear objectives, relevant KPIs and suitable technologies are derived from this. A strong data culture and the continuous development of the strategy are crucial to success.
IT creates the technological basis for data availability, scalability and security. Together with the specialist departments, it ensures that data solutions are implemented in a practical and strategic manner.
Data strategy consulting supports companies in systematically harnessing their data – from analyzing the current situation to defining strategic goals and developing specific measures. It provides technical and organizational support during implementation and ensures that data solutions are geared towards measurable business value.
It aims to make better use of the potential of data for society and the economy – through a trustworthy infrastructure, high data protection standards and the promotion of digital sovereignty. The focus is on the development of data platforms, cooperation with industry and research as well as AI applications.