





Ihre Daten,
Ihr Wissen,
Ihr Vorteil.

Data is Business – Eine mit dieser Maxime konsequent durchdachte Datenstrategie Beratung stellt weit mehr dar als ein technisches Instrument: Die Datenstrategie fungiert als Leitplanke für datengetriebene Entscheidungen, ebnet den Weg für KI- und Analytics-Initiativen und bildet das Fundament moderner Plattformarchitekturen. Sie sichert zudem Datenqualität, etabliert Governance-Strukturen und stärkt die Resilienz gegenüber Markt- und Regulierungsdynamiken. Gleichzeitig konsolidiert sie Datenströme, beseitigt Silos und fördert effiziente, unternehmensübergreifende Zusammenarbeit. So wird sie zum Stabilisator in volatilen Zeiten, zum Beschleuniger von Entscheidungsprozessen und ROI sowie zum strategischen Asset für nachhaltige Innovation und systematische Wissensnutzung.

Die Bedeutung einer Datenstrategie Beratung für die digitale Transformation
Strategisch erschlossene und operativ zugängliche Daten bilden die Grundlage fundierter Entscheidungen und dienen als Katalysator für zukunftsweisende Innovationen und Wachstum. Wer datengetriebene Fähigkeiten und Technologien effizient und unternehmensspezifisch adaptiert, nutzt Chancen proaktiv.
Eine konsequent umgesetzte Datenstrategie mit unternehmensweiter Governance und systematischem Metadatenmanagement bildet das Rückgrat jeder Compliance-Initiative. Sie garantiert die lückenlose Erfüllung von Anforderungen wie Digitalen Produktpässen, CSRD und weiteren Reporting-Richtlinien – nicht nur im eigenen Unternehmen, sondern entlang der gesamten Lieferkette. Kernstück ist eine modell-basierte Datenintegrationsschicht, die relevante Informationen zentral sammelt, fortlaufend aktualisiert und flexibel an neue Regularien anpasst. So werden Reporting-Tools zuverlässig und ohne manuellen Mehraufwand gespeist, Risiken minimiert und die Reaktionsfähigkeit auf sich ändernde Vorgaben beschleunigt.
Das Ergebnis: stressfreie Compliance, ein deutlich reduziertes Risikoprofil und ein spürbar gestärktes Vertrauen von Kunden, Investoren und Aufsichtsbehörden – eine belastbare Basis für nachhaltiges Wachstum.
Moderne Datenstrategien bündeln Kundendaten aus allen Kanälen – von Online-Interaktionen bis zum stationären Einkauf – in einer zentralen Plattform und schaffen damit die Basis für fundierte Datenanalysen. Eine klare Datenverwaltung standardisiert und kontrolliert sämtliche Datenflüsse, sodass ein verlässliches Kundenprofil entsteht, das genau auf individuelle Bedürfnisse eingeht. Ergänzt um ein durchdachtes Metadatenmanagement werden semantische Zusammenhänge sichtbar: Verhaltensmuster, Vorlieben und Interaktionshistorien lassen sich präzise erfassen und interpretieren.
Auf dieser soliden Grundlage entstehen Customer-Experience-Lösungen, die weit über Standardmaßnahmen hinausgehen. Angebote und Kommunikationsstrategien werden automatisch in dem Moment generiert, in dem sie den größten Mehrwert liefern. Und weil Daten über ein strukturiertes Need2Share-Konzept nahtlos zwischen Marketing, Vertrieb und Kundenservice ausgetauscht werden, profitieren alle Bereiche von derselben, stets aktuellen Informationsbasis.
Feingranulare Datenschutzprinzipien sorgen schließlich dafür, dass persönliche Daten effizient geschützt und gleichzeitig für berechtigte Analysen verfügbar bleiben.
Eine durchgängig angelegte Datenstrategie, die Metadatenmanagement mit semantischer Kontextualisierung verbindet, erschafft einen zentralen Wissensspeicher, das nicht länger an Einzelpersonen hängt. Sämtliche Informationen – von bewährten Prozessen bis hin zu langjährigem Fachwissen – werden strukturiert erfasst, im richtigen Kontext dokumentiert und abteilungsübergreifend nutzbar gemacht. Gerade im demografischen Wandel, wenn erfahrene Kolleginnen und Kollegen in den Ruhestand wechseln, sichert dieses Vorgehen essenzielle Expertise und verhindert Wissensverluste. Gleichzeitig skaliert die semantische Aufbereitung individuelles Know-how, ordnet es in einen Gesamtzusammenhang ein und fördert so den interdisziplinären Austausch sowie die Entstehung neuer Erkenntnisse – eine unverzichtbare Basis für nachhaltige Innovation und langfristigen Unternehmenserfolg.
Eine ganzheitliche Datenstrategie, die Governance, Metadatenmanagement und Need2Share-Ansatz vereint, legt das Fundament für leistungsstarke KI-Anwendungen im Unternehmen. Erst wenn sämtliche Datenquellen konsistent standardisiert, semantisch angereichert und technisch harmonisiert sind, entfalten Modelle ihr volles Potenzial: Sie liefern passgenaue Analysen, präzise Prognosen und schaffen belastbare Grundlagen für strategische Entscheidungen. Fehlt dieser systematische Rahmen, drohen fragmentierte Informationen, fehleranfällige Auswertungen und der Rückgriff auf generische KI-Funktionen – ein Verlust an Wettbewerbsdifferenzierung und Effizienz.
Gleichzeitig sorgt eine transparente Datenverwaltung mit klar definierten Rollen, Verantwortlichkeiten und Freigabeabläufen nicht nur für die sichere Einhaltung regulatorischer Vorgaben, sondern stärkt auch die bereichsübergreifende Zusammenarbeit. Relevante Informationen stehen in Echtzeit bereit, Innovationen lassen sich schneller skalieren, und neue Geschäftsmodelle entstehen aus dem Zusammenwirken aller Fachbereiche. So wird KI nicht nur zum technischen Spielball, sondern zum nachhaltigen Motor für Effizienz, Wachstum und langfristige Marktführerschaft.
Der übergreifende Austausch von Daten entlang der Lieferkette avanciert zum kritischen Erfolgsfaktor: Industriepartnerschaften und regulatorische Vorgaben verlangen eine durchgängige, fehlerfreie Datenpipeline, die Transparenz und Vertrauen schafft. Eine ganzheitliche Datenstrategie definiert gemeinsam getragene Datenmodelle und -semantik, legt fest, welche Informationen in welchem Kontext benötigt werden, und verhindert so Missverständnisse und Inkonsistenzen. Standardisierte Formate – sei es über APIs, Streaming oder klar beschriebene Data Assets – sorgen für einen reibungslosen Datentransfer zwischen den jeweiligen IT-Systemen und ermöglichen eine nahtlose Prozessintegration.
Ein weiterer Hebel liegt in der einfachen Anbindung an branchenübergreifende Datenräume wie CatenaX oder ManufacturingX im Gaia-X-Ökosystem. Wer bereits ein strukturiertes Rahmenwerk für Datenverwaltung und Metadatenmanagement etabliert hat, kann diese Plattformen effizient nutzen, um Echtzeitdaten auszutauschen, Kooperationen zu vertiefen und gemeinsam neue Wertschöpfungspotenziale zu heben.
Eine ganzheitlich verankerte Datenstrategie verbindet Produktionsdaten aus allen Standorten und Anlagenvarianten zu einer einheitlichen Informationsbasis. Klare Zuständigkeiten und verbindliche Qualitätsstandards sorgen dafür, dass sämtliche Daten – unabhängig von ihrer Herkunft – konsistent und vertrauenswürdig aufbereitet werden. Ein integriertes Metadatenmanagement verleiht den Rohdaten semantische Tiefe, indem es Maschinenparameter, Standortdetails und Prozessvarianten in den richtigen Kontext setzt. Auf diesem Fundament eröffnen sich AI-Use-Cases, die weit über klassisches Predictive Maintenance hinausreichen.
So lassen sich Wartungsbedarfe nicht nur frühzeitig erkennen, sondern direkt in geplante Produktionsfenster integrieren. Die Folge: eine synchrone Steuerung von Wartungszyklen, Produktionskapazitäten und Lieferkettenprozessen – Basis für skalierbare, unternehmensweite Entscheidungssysteme. Das Ergebnis ist eine spürbare Optimierung der Produktionsplanung und eine resilientere Supply-Chain.
Für die Automatisierung aller Geschäftsprozesse liefert diese Datenbasis die nötige Geschwindigkeit und Transparenz. In Kombination mit modernem Process Mining lassen sich Abläufe detailliert analysieren, Engpässe aufdecken und Automatisierungspotenziale systematisch heben. Redundanzen werden eliminiert, Ressourcen punktgenau eingesetzt und die Organisation gewinnt an Agilität. Insgesamt führt dieses Zusammenspiel zu erheblichen Effizienzsteigerungen, deutlichen Kosteneinsparungen und einem nachhaltigen Vorsprung im global vernetzten Produktionsumfeld.
Zentrale Handlungsfelder zur Realisierung der Datenstrategie
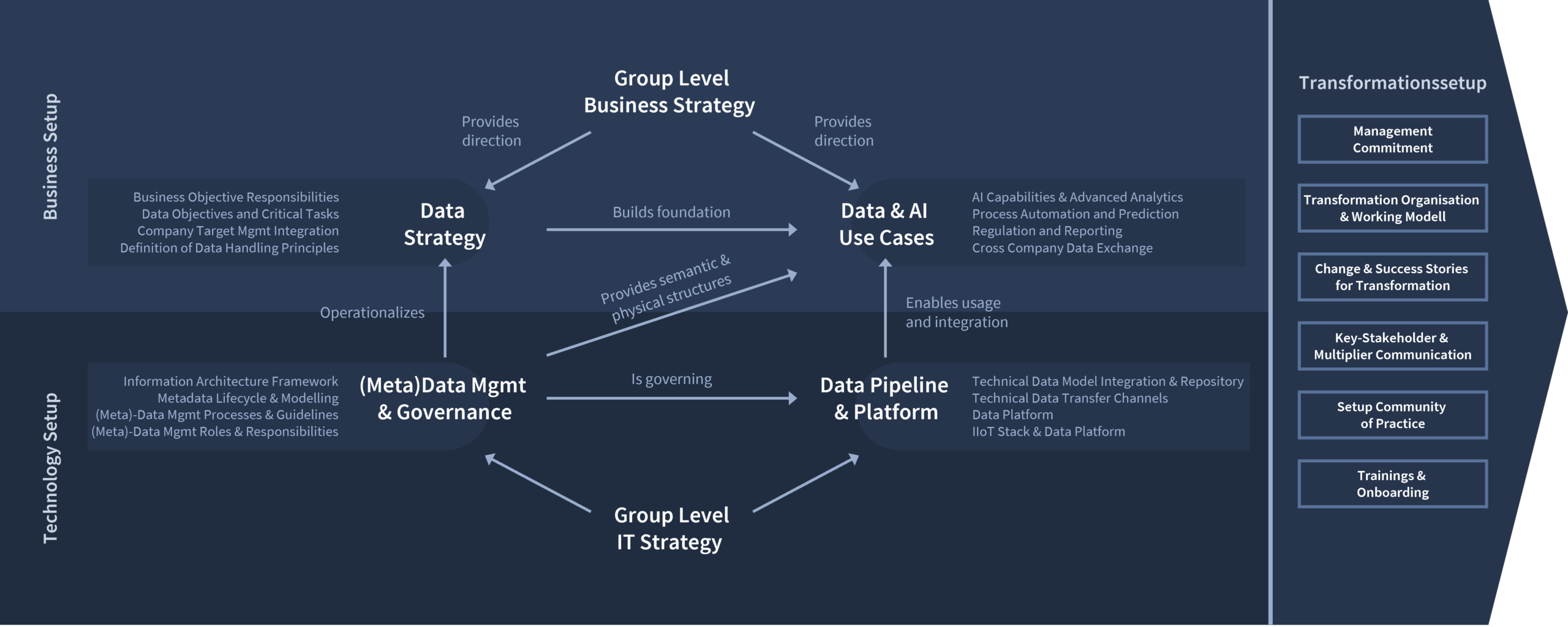
Die Realisierung einer wirksamen Datenstrategie beruht auf sechs zentralen Handlungsfeldern: Unternehmens- und Daten-Strategie, Use-Case-Entwicklung, Governance-Strukturen, Data Pipelines und dem Transformationssetup. Das Zusammenspiel der einzelnen Handlungsfelder schafft eine nahtlose und eng miteinander verbundene Wertschöpfungskette:
Fachabteilungen leiten aus der Unternehmensstrategie eine präzise Datenroadmap ab und entwickeln darauf Use Cases mit klarem, messbarem Business Value. Metadatenmanagement und Data Governance legen die semantische und organisatorische Basis, während flexible Plattformarchitekturen für die Datenintegration Performance und Agilität auf technischer Ebene sichern.
Ventum Consulting orchestriert diesen End-to-End-Prozess, um die Datenreife systematisch zu steigern. So wird „Data is Business“ im gesamten Unternehmen zur gelebten Realität und treibt nachhaltigen Erfolg voran.
Eine klar definierte Business Strategy legt nicht nur Wachstumspfade fest, sondern setzt zugleich die Leitplanken für eine wirkungsvolle Datenstrategie. Daten sind kein IT-Insellösungsprojekt, sondern integraler Erfolgsfaktor: „Data is Business“. Erst wenn die Fachbereiche Verantwortung für Inhalte, Zielsetzungen und Rollen übernehmen, verankert sich die Datenstrategie durch alle Ebenen hindurch. So gewinnen datengetriebene Vorhaben die nötige Akzeptanz und Schlagkraft, um langfristig echten Mehrwert zu schaffen.
Als operativer Blueprint für den datengestützten Erfolg übersetzt die Datenstrategie die Business Strategy in klare Data Objectives und Critical Tasks. Eingebettet ins Target Management, definiert sie messbare Ergebnisse – von KI-Insights über automatisierte Prozesse bis hin zu Reporting – sowie die jeweils verantwortlichen Rollen. Verbindliche Data-Handling-Principles garantieren eine konsistente Erhebung, Verarbeitung und Weitergabe sämtlicher Daten. So entsteht durchgängige Transparenz darüber, wo Daten Mehrwert schaffen, wer diesen liefert und nach welchen Standards im gesamten Unternehmen gearbeitet wird. Dieses orchestrierte Zusammenspiel verleiht der Datenstrategie die nötige Schlagkraft, um Daten zum Treiber von Wachstum und Innovation zu machen.
Aus einer durchdachten Datenstrategie lassen sich Data & AI Use Cases ableiten, die echten Business-Mehrwert schaffen: KI- und Advanced-Analytics-Lösungen decken verborgene Zusammenhänge auf, Process Automation & Prediction eliminiert manuelle Routinetätigkeiten und liefert präzise Planungsprognosen. Ein strukturierter Regulation-&-Reporting-Ansatz automatisiert Management-Reports und sichert die Einhaltung aller Compliance-Vorgaben. Nicht zuletzt eröffnen Cross-Company Data Exchanges mit klar definierten Zugriffs- und Sicherheitsregeln völlig neue Kooperationsmodelle mit Partnern und Lieferanten.
Ein belastbares Metadatenmanagement und eine stringente Data Governance bilden die Voraussetzung für zuverlässige Use Cases. Ein Information Architecture Framework definiert Aufbau und Lebenszyklus der Datenmodelle sowie die Entstehung und Aktualisierung aller Metadaten. Klare, dokumentierte Data-Management-Prozesse und -Guidelines ergänzen dies um verbindliche Abläufe, während eindeutig zugeordnete Rollen – vom Data Steward über den Data Owner bis zum Data Engineer – Verantwortlichkeiten festlegen. So entsteht nicht nur eine gemeinsame „Datensprache“, sondern auch eine solide Basis für Qualität, Transparenz und vollständige Nachvollziehbarkeit aller Datenflüsse.
Der technologische Baustein ist schließlich die Data Integration Platform, welche die technische Umsetzung der Use Cases ermöglichen. Moderne Setups speichern und orchestrieren große Datenmengen und fokussieren auf modell-basierte Integration und Prozessierung der unterschiedlichsten Quellen. Daten Transfer Channels – von Streaming APIs bis zu KI-Agenten – garantieren, dass Informationen in Echtzeit oder nach definierten Intervallen anwendungsbezogen bereitgestellt werden. Ergänzt wird das Setup in produzierenden Unternehmen sowie Anlagenanbietern- und Betreibern durch IIoT Stacks und Edge Plattformen, die Sensordaten erfassen und in die zentrale Datenlandschaft einspeisen. Gemeinsam stellen diese Infrastrukturen sicher, dass alle Use Cases performant, sicher und skalierbar betrieben werden können.
Zwischen Digital Leadership, Business und IT entscheidet das richtige Transformations‐Setup über den Erfolg einer Data-Driven Enterprise. Erst in einem integrierten Rahmenwerk entfalten Architektur, Use Cases, Metadatenmanagement und Plattformen ihr volles Potenzial:
- Management-Commitment
Klare Zielvorgaben, ausreichend Budget und sichtbare Unterstützung auf Top Management Ebene schaffen den Handlungsrahmen für alle weiteren Schritte. - Transformationsorganisation & Operating Model
Eindeutige Rollen und Verantwortlichkeiten über Fach- und IT-Silos hinweg sorgen für reibungslose Abläufe und beschleunigen Entscheidungen. - Change Management & Kommunikation
Gezielter Abbau von Widerständen, Förderung von digitalen Führungskompetenzen und aktives Stakeholder-Engagement sichern die Akzeptanz von Mitarbeitenden im gesamten Unternehmen. - Community of Practice & Upskilling
Kontinuierlicher Wissensaustausch, Best-Practice-Formate sowie strukturierte Trainings- und Onboarding-Programme fördern die Kompetenzentwicklung und verankern datengetriebene Methoden nachhaltig.
Datenstrategie - Reifegrad Assessment
Step-by-Step zur Implementierung Ihrer Datenstrategie

Unser dreiphasiges Datenstrategie-Reifegrad-Assessment erfasst Ihren Ist-Zustand, deckt Optimierungspotenziale auf und liefert einen klaren Maßnahmenplan statt reiner Einstufungen. Die Phasen sind ausgerichtet an Ihren Use Cases und einsetzbar als Benchmark für neue sowie abgeschlossene Projekte.
Durch die ganzheitliche Analyse aller Kernkomponenten – von Data Governance über Metadatenmanagement und Need2Share bis hin zu Data-Pipelines – entsteht eine objektive Bewertung Ihres Datenmanagements. Mit den daraus abgeleiteten, umsetzbaren Empfehlungen erhalten Sie einen strukturierten Fahrplan, mit dem Sie Ihr Use-Case-Portfolio und Transformationsprogramm auf einen höheren Reifegrad heben, skalieren und nachhaltig weiterentwickeln können. Verstehen, wo Sie stehen. Wissen, was zu tun ist.
Mit unserem Reifegrad-Assessment durchlaufen Sie einen klar strukturierten Prozess in drei Schritten.
Der Hebel für den Sprung
zur nächsten Reifegradstufe
Stufe 01
Explorieren & Bewerten
In Stufe 1 laufen alle Szenarien als isolierte PoCs – manuell aufwendig und technisch begrenzt. Sie eignen sich zum schnellen Erkenntnisgewinn, erreichen aber nicht die nötige Tiefe für den produktiven Betrieb. Erst klare Governance, systematisches Metadatenmanagement, Need2Share-Mechanismen und automatisierte Pipelines schaffen eine skalierbare Grundlage.
- Compliance und Regulation
Umsetzbar: Manuelles Erfassen relevanter Kennzahlen (z. B. CO₂‑Werte oder Produktpässe) via CSV‑Export und Excel‑Reporting.
Limitierung: Keine automatisierte Datenlinie, geringe Auditierbarkeit und hohes Fehlerrisiko bei regulatorischen Änderungen. - Customer Experience und Customer Data Protection
Umsetzbar: Manuelle Segmentierung von Kundenlisten in Excel, Versand statischer Mailings.
Limitierung: Keine dynamischen Profile, kein feingranularer Datenschutz, getrennte Silos zwischen Marketing und Service. - Daten als Wissensspeicher
Umsetzbar: Einzelne Experten dokumentieren Erkenntnisse lokal in Dokumenten oder Excel.
Limitierung: Keine zentrale Auffindbarkeit, fehlende semantische Vernetzung, hoher Pflegeaufwand und Wissensverlust bei Personalwechsel. - KI‑Anwendungen
Umsetzbar: Nutzung bestehender KI-Lösungen „von der Stange“ zur Unterstützung manueller Arbeit sowie Offline‑Training einfacher Modelle auf kleinen, manuell aggregierten Datensätzen (z. B. Vibrationswerte für Predictive Maintenance).
Limitierung: Datenqualität inkonsistent, kein semantischer Kontext, nicht reproduzierbar und kaum skalierbar auf weitere Anlagen oder Use Cases. - Produktionsdaten & integrierte KI Use Cases
Umsetzbar: Lokal per Hand ausgelesene Sensorwerte als CSV in ein PoC‑Tool laden und manuelle Auswertung.
Limitierung: Keine übergreifende Sicht auf Standorte/Anlagenvarianten, kein Echtzeit‑Streaming und keine Prozess‑ oder Supply‑Chain‑Orchestrierung. - Cross Company Collaboration
Umsetzbar: Abstimmung per E-Mail mit Partnern, manuelles Versenden von Dateien oder dedizierte Umsetzung per lokaler Schnittstellen.
Limitierung: Fehlende Standardformate, kein gemeinsames Datenverständnis, zeitaufwendig und fehleranfällig. - Operative Effizienz und Automatisierung
Umsetzbar: Basis-Prozessmapping per Interviews, Auswertung von Log-Dateien in Excel.
Limitierung: Keine Echtzeit-Transparenz, keine Automatisierung, fehlende Integration mit Celonis oder anderen Mining-Tools.
- Compliance und Regulation
Fazit: Stufe 1 ist ideal, um erste Erfahrungen zu sammeln und Use Cases grob zu skizzieren. Für den produktiven Betrieb und die Skalierung aller beschriebenen Szenarien sind jedoch strukturierte Data Governance, Metadatenmanagement, Need2Sahre-Mechanismen und automatisierte Data Pipelines erforderlich.

Übergang:
Stufe 1 zu Stufe 2
Der Übergang markiert den Schritt von vereinzelt prototypischen Datenexperimenten hin zu ersten tragfähigen Minimal-Viable-Products (MVPs) und initialen produktiven Data Use Cases.
Schlüsselaufgaben:
- Verantwortungsmodell definieren und verankern
Richten Sie ein Verantwortungsschema auf Basis der gelebten Praxis ein und dokumentieren Sie klar, wer für Entscheidungen, Qualitätssicherung und Eskalationen bei jedem Datenobjekt zuständig ist. - Policies und Prozesse formalisieren
Entwickeln Sie verbindliche Richtlinien zu Datenqualität, Compliance und Datenschutz und integrieren Sie diese in Ihre Standard-Arbeitsabläufe (z. B. Change-Requests, Ticket-Systeme), um eine konsistente Umsetzung sicherzustellen. - Monitoring- und Audit-Fähigkeiten implementieren
Erstellen Sie Dashboards zur Echtzeit-Überwachung von Datenqualitäts- und Compliance-Kennzahlen, automatisieren Sie regelmäßige Audit-Reports und informieren Sie Verantwortliche bei Abweichungen. - Change-Management und Schulung durchführen
Führen Sie praxisorientierte Schulungen für alle Stakeholder und Mitarbeitenden durch, etablieren Sie einen kontinuierlichen Review- und Lessons-Learned-Zyklus und passen Sie Richtlinien anhand der Pilot-Erfahrungen fortlaufend an.
- Use-Case-Metadatenkatalog einrichten
Implementieren Sie für die Use Cases einen dedizierten Katalog zur Metadatenbeschreibung und Verknüpfung mit Prozessen und IT-Systemen. - Taxonomie und Glossar definieren
Arbeiten Sie eng mit den Fachbereichen zusammen, um zentrale Geschäftsbegriffe und Datenklassen zu identifizieren und in einem Glossar als Geschäftsobjekte festzuhalten. - Metadaten-Templates in Pipelines integrieren
Verankern Sie standardisierte Vorlagen für Feldbeschreibungen, Herkunftsangaben und Qualitätskennzahlen in den bestehenden ETL-Jobs oder Integrationsskripten der Use Cases. - Semantische Annotation praxisnah umsetzen
Legen Sie Regeln fest, wie physische Datenelemente mit Geschäftsobjekten (z. B. Messpunkt, System, Geschäftsobjekt) verknüpft werden, und dokumentieren Sie diese direkt im Katalog. - Review- und Pflegeprozesse starten
Bestimmen Sie für jeden Use Case einen Data Steward, der Metadaten regelmäßig auf Vollständigkeit und Aktualität prüft und Anpassungen vornimmt. Verankern Sie dieses Vorgehen in der Data Governance. - Schulung der Pilotteams
Führen Sie kompakte Workshops durch, in denen Entwickler und Fachanwender lernen, Metadaten korrekt zu erfassen, zu nutzen und die zentralen Templates anzuwenden.
- Use-Case-bezogene Sharing-Richtlinien definieren
Legen Sie für jeden Use Case fest, welche Daten nur auf Basis eines dedizierten Zugriffsgrundes verfügbar sind („Need to Know“) und welche Daten unternehmensweit oder bereichsspezifisch frei zugänglich sind („Need to Share“). - Freigabe-Workflow implementieren
Richten Sie einen standardisierten Genehmigungsprozess ein (z. B. per Ticket-System oder E-Mail-Template), in dem die Verantwortlichen für den jeweiligen Use Case Datenanfragen prüfen und freigeben. - Datenangebote klar formulieren
Nutzen Sie die Metadaten, um verfügbare Datensätze transparent und anwenderfreundlich „ins Schaufenster“ zu stellen und so allen Nutzern einfachen Zugang zu ermöglichen. - Training und Dokumentation bereitstellen
Schulen Sie Pilotteams im Freigabe-Workflow und im Umgang mit dem Datenverzeichnis, und erstellen Sie kurze How-to-Guides, damit der Prozess von allen Beteiligten einheitlich angewendet wird.
- Use-Case-Scope und Datenquellen festlegen
Definieren Sie für jeden Use Case, welche Systeme oder Sensoren anzubinden sind, welche Formate und Frequenzen erforderlich sind, und erfassen Sie diese in einer Architekturübersicht mit Verknüpfung zu den semantischen Metadaten. - Manuelle Exporte durch ETL-Jobs ersetzen
Tauschen Sie Ad-hoc-CSV-Exporte gegen automatisierte Skripte oder einfache Workflow-Tools aus, die Daten regelmäßig extrahieren und laden. - Konnektoren und APIs einrichten
Implementieren Sie für jeden Use Case IoT-Gateways, REST-API-Clients oder Datenbank-Konnektoren, um Quellsysteme zuverlässig an Ihre Pipeline anzubinden. - Datenaufbereitung und -transformation standardisieren
Entwickeln Sie wiederverwendbare Transformationsmodule in Ihren ETL-Jobs und parametrisieren Sie diese für verschiedene Datenschemata. - Basis-Orchestrierung und Scheduling konfigurieren
Nutzen Sie ein leichtgewichtiges Orchestrierungs-Tool oder einen Scheduler, um ETL-Jobs zeitgesteuert auszulösen und Abhängigkeiten (z. B. zwischen Extraktion und Laden) abzubilden. - Logging, Monitoring und Fehler-Handling sicherstellen
Richten Sie zentralisierte Logdateien, automatisierte Alerts und Retry-Mechanismen ein, damit Pipeline-Fehler frühzeitig erkannt und behoben werden können. - Dokumentation und Deployment-Pipelines etablieren
Pflegen Sie eine kurze, versionierte Dokumentation Ihrer Pipeline-Konfigurationen und richten Sie CI/CD-Pipelines ein, um Änderungen kontrolliert in die Pilotumgebung zu übernehmen.
- Digital Leadership stärken
Identifizieren Sie Fähigkeitslücken und entwickeln Sie ein modernes Führungskonzept mit klaren Rollen und Verantwortlichkeiten für eine erfolgreiche Unternehmensführung im digitalen Zeitalter. - Daten-Vision und Strategie kommunizieren
Entwickeln Sie eine klare, unternehmensweite Botschaft, die den Nutzen datengetriebener Prozesse erläutert, und platzieren Sie sie in Leadership-Meetings sowie in internen Kommunikationskanälen. Verweisen Sie dabei auf bereits existierende oder in Umsetzung befindliche Use Cases und zeigen Sie, wie diese auf die Datenstrategie einzahlen. - Executive Sponsorship sichern
Stellen Sie sicher, dass C-Level bzw. Geschäftsführung und Bereichsleiter als Fürsprecher auftreten, verbindliche Ziele für Use Cases definieren und Budgets für Dateninitiativen freigeben. - Data Champions und cross-funktionale Teams etablieren
Benennen Sie „Data Champions“, die als Multiplikatoren fungieren, und bilden Sie bereichsübergreifende Arbeitskreise für Austausch und Zusammenarbeit. - Data Literacy und Awareness fördern
Führen Sie zielgruppenspezifische Workshops und Schulungen durch, um Grundlagenwissen zu Daten, Tools und Methoden zu vermitteln und das Bewusstsein für datengetriebene Wertschöpfung zu schärfen. - Incentives und Erfolgsmessung einführen
Verankern Sie datenstrategie-bezogene KPIs in Zielvereinbarungen und honorieren Sie Erfolge aus Projekten, um Motivation und Akzeptanz zu steigern. - Change Agents und Community aufbauen
Installieren Sie ein Netzwerk engagierter Stakeholder, das regelmäßig Lessons Learned teilt, Best Practices dokumentiert, Innovation fördert und Mitarbeitende bei Hürden aktiv unterstützt. - Innovation Hubs verankern
Etablieren Sie gezielte Formate zur Weiterentwicklung und Förderung eines zukunftsfähigen, datengetrieben Unternehmens.
- Enterprise-Architektur-Blueprint aufbauen
Beginnen Sie, Daten-, Anwendungs- und Infrastrukturmodelle in einem Architektur-Repository zu definieren. Etablieren Sie dabei einheitliche Ebenen, Viewpoints und Artefakt-Templates. Stellen Sie sicher, dass alle neuen Use Cases auf dieser konzeptionellen Basis aufsetzen, um Wiederverwendung und Konsistenz zu fördern. - Vorgehensmodell definieren und operationalisieren
Etablieren Sie ein leichtgewichtiges, iteratives Framework, das Fach- und IT-Bereiche team-basiert zusammenführt und klare Rollen sowie Artefakte (Backlog, User Stories, Akzeptanzkriterien) definiert. Regelmäßige Review-Zyklen Ihrer Use Cases ermöglichen schnelle Korrektur- und Feedback-Schleifen. - Methodentemplates und Best Practices bereitstellen
Erarbeiten Sie standardisierte Vorlagen und Checklisten für den Rollout der Datenverwaltung, Metadatenpflege, Pipeline-Automatisierung und Freigabe-Workflows. Stellen Sie diese Artefakte allen Projektteams zur Verfügung und integrieren Sie sie in das bestehende oder im Aufbau befindliche Architekturvorgehen Ihrer Organisation. - Lessons-Learned-Prozess implementieren
Führen Sie nach jedem Pilot eine strukturierte Retrospektive durch, dokumentieren Sie Erfolge und Herausforderungen und übertragen Sie gewonnene Erkenntnisse in die nächste Projektrunde. Teilen Sie die Schlüsselerkenntnisse organisationsweit. - Schulung, Coaching und Mentoring anbieten
Bieten Sie gezielte Trainings zur Datenstrategie, zum Metadatenmanagement und zur Pipeline-Orchestrierung an. Etablieren Sie ein internes Netzwerk von Experten („Data Coaches“), die Pilot-Teams in methodischen und technischen Fragestellungen unterstützen.
Bereit für den nächsten Schritt?
Für den nächsten Schritt gilt es nun, erste formale Strukturen, Prozesse und Werkzeuge aufzusetzen, die eine skalierbare Pilotierung datengetriebener Anwendungen ermöglichen.
Stufe 02
Pilotieren & Lernen
In Stufe 2 entstehen erste Mehrwerte – halbautomatisierte Reports, spezialisierte KI-Modelle, Data Products und API-Piloten. Für eine nahtlose Skalierung und Übertragung auf weitere Use Cases fehlen jedoch unternehmensweit einheitliche Governance, semantisches Metadatenmanagement, automatisierte Pipelines und ein zentrales Need2Share-System.
- Compliance und Regulation
Umsetzbar: Für definierte Bereiche werden Kennzahlen (z. B. CO₂‑Emissionen, Produktpässe) automatisiert per ETL‑Job aus den Kernsystemen extrahiert. Data Owner definieren einheitliche Validierungsregeln, Metadaten beschreiben Datenquellen und -verwendungszwecke. So entstehen halbautomatisierte Reports, die regelmäßig für interne oder regulatorische Zwecke genutzt werden können.
Limitierung: Die automatisierten Pipelines und Freigabeprozesse gelten nur für ausgewählte Use Cases – bei neuen Berichtspflichten oder weiteren Domänen sind weiterhin dedizierte Anpassungen und CSV‑Exporte nötig, die konzeptionell und technisch spezifisch erarbeitet werden müssen. - Customer Experience und Customer Data Protection
Umsetzbar: Kundendaten aus dedizierten Kanälen werden in eine Cloud‑Datenbank eingespeist, semantisch angereichert und in einer BI‑Sandbox für personalisierte Kampagnen genutzt. Die Verantwortlichen für die Use Cases definieren feingranulare Datenschutzregeln, die bei der Segmentierung und Ausspielung berücksichtigt werden.
Limitierung: Die Umsetzung gilt nur für ausgewählte Marketing‑ oder Service‑Use Cases. Ein ganzheitliches Customer‑Data‑Platform‑Setup mit unternehmensweitem Rollen‑ und Rechte‑Management sowie der entsprechenden semantischen Beschreibung fehlen bislang. - Daten als Wissensspeicher
Umsetzbar: Erste „Data Products“ oder „Data Assets“ sind katalogisiert und über Metadaten‑Glossare, Modellierungen und Taxonomien wird das dahinterliegende Know‑how zusammengefasst. Die semantische Beschreibung der Daten oder besser gesagt Geschäftsobjekte ermöglicht schnellen inhaltlichen Zugang und Verständnis – unabhängig von der Verfügbarkeit von Experten.
Limitierung: Das Wissensnetzwerk deckt bislang nur die definierten Use Cases ab und durch die fehlende unternehmensweite Ontologie ist der inhaltliche Zugang noch nicht flächendeckend gegeben. Eine unternehmensweite Vernetzung und übergreifende Wissensgraphen sind noch nicht etabliert. Außerdem ist oft das semantische Wissen nicht mit den physikalischen Datenmodellen und Quellsystemen verbunden. - KI‑Anwendungen
Umsetzbar: Über technische Schnittstellen werden die relevanten Datensätze aus den Quellsystemen geladen, aufbereitet und aggregiert. Auf dieser Basis können ML‑Modelle auf konsistent vorvalidierten Daten trainiert werden (z. B. Predictive Maintenance für definierte Anlagenvarianten) oder für bestehende Modelle als Input und Kontext – Stichwort: „semantic prompting“ – bereitgestellt werden. Metadaten dokumentieren Modellparameter und Datenherkunft, wodurch auf den Use Case spezifische Algorithmen und Wissen genutzt werden können.
Limitierung: Qualitätssicherungsregeln und semantische Kontexte existieren nur in den Use Cases und sind nicht übergreifend zugänglich und verständlich. Die Skalierung auf weitere Use Cases oder Erweiterung in andere Geschäftsbereiche erfordert zusätzlichen manuellen Aufwand und lokale Metadaten‑Erweiterungen. Zusätzlich sind die Use Cases meist isoliert und bilden nur bestimmte Funktionsbereiche ab. - Produktionsdaten & integrierte KI‑Use Cases
Umsetzbar: Dedizierte Pipelines übertragen Sensordaten aus Anlagen über Data Assets oder Streaming‑Services. Damit haben Techniker standardisierten Zugriff auf Funktionen wie Predictive Maintenance oder Produktionsplanungsunterstützung.
Limitierung: Die Orchestrierung der einzelnen Use Cases bedarf weiterhin der aktiven Steuerung durch Techniker oder entsprechende Experten. Die Use Cases sind nicht oder nur geringfügig inhaltlich verbunden. Standorte oder Anlagenvarianten müssen dediziert und einzeln hinzugefügt werden. Eine unternehmensweite Prozess‑ und Supply‑Chain‑Orchestrierung existiert noch nicht. - Cross Company Collaboration
Umsetzbar: Über API‑Schnittstellen mit Partnern werden für definierte Anwendungsfälle standardisierte Datenformate (z. B. IoT‑Messwerte oder Produktstammdaten) ausgetauscht. Freigaben folgen dem Need2Know‑Prinzip: jeder Datentransfer wird fallbasiert geprüft und über definierte Workflows freigegeben.
Limitierung: Nur ausgewählte Partner und Use Cases sind angebunden. Für weitere Lieferketten‑Szenarien fehlt die zentrale Plattform und ein unternehmensweites Freigabemanagement. - Operative Effizienz und Automatisierung
Umsetzbar: Log‑Daten ausgewählter Kernprozesse werden automatisiert per ETL‑Job in die Process‑Mining‑Plattform eingespeist. Erste Process‑Mining‑Analysen zeigen Engpässe und liefern Handlungsfelder für Pilot‑Automatisierungen (z. B. Workflow‑Trigger für Freigabeprozesse).
Limitierung: Die Process‑Mining‑Integration beschränkt sich auf einzelne Prozessdomänen und läuft nicht in Echtzeit. Eine durchgängige Automatisierung und ein unternehmensweites Monitoring sind noch nicht realisiert.

Übergang:
Stufe 2 zu Stufe 3
Der Übergang bedeutet, erfolgreiche MVP‑Projekte und isolierte Use Cases in ein unternehmensweites, durchgängiges sowie in weiten Teilen tool-basiertes Data Management Framework zu transformieren.
Schlüsselaufgaben:
Enterprise-Data-Governance-Rahmenwerk aufsetzen
Definieren Sie ein plattformübergreifendes Framework mit einheitlichen Prinzipien für Prozesse, Rollen, Richtlinien und Tools – basierend auf einem standardisierten Referenzmodell statt lokaler Insellösungen. Beziehen Sie Datenlieferanten und -nutzer gleichermaßen ein und stellen Sie sicher, dass alle Schritte der Datenwertschöpfung von der strategischen Planung bis zur Ausspielung der „Payload“ abgedeckt sind.Rollen- und Verantwortlichkeitsmodell harmonisieren
Vereinheitlichen Sie Datenrollen wie Data Steward und Data Architect in allen Bereichen, dokumentieren Sie Zuständigkeiten in einem zentralen RACI-Schema und verankern Sie diese in Stellen- sowie Service-Level-Agreements.Strategische Datenbedarfe in Use-Case-Roadmap übersetzen
Führen Sie Workshops mit Datenlieferanten und -nutzern durch, um strategische Anforderungen in konkrete Use Cases und operative Datenvorgaben zu überführen und priorisiert in Ihr Governance-Framework einzubetten.Data Governance nutzerorientiert etablieren
Legen Sie Data-Governance-Schritte anhand umsetzungsorientierter Nutzungsszenarien und User Journeys für Datenkonsumenten und -lieferanten fest und verknüpfen Sie diese mit Ihren Use Cases im übergreifenden Framework.Governance-Community und Change Management stärken
Richten Sie bereichsübergreifend ein Data Governance Council ein, fördern Sie regelmäßige Austauschformate und Lessons-Learned-Reviews, um Richtlinien iterativ anzupassen und eine datengetriebene Kultur nachhaltig zu verankern.
Zentrales Metadaten-Repository aufbauen
Konsolidieren Sie Use-Case-Lexika in einem plattformübergreifenden Katalog und verknüpfen Sie Data Products, Pipelines und Geschäftsobjekte semantisch. Binden Sie Datenlieferanten und -nutzer in Workshops ein, um Terminologie und Abhängigkeiten gemeinsam zu definieren. Entwickeln Sie eine unternehmensweite Ontologie und Taxonomie und verankern Sie Pflege wie Weiterentwicklung im Data-Governance-Framework.Automatisierte Metadaten-Pipeline implementieren
Etablieren Sie Pipelines, die semantische Änderungen toolgestützt direkt in physische Schemas überführen und bei Bedarf auf Streaming-Services oder Data Assets anwenden. Richten Sie ein Schema-Mapping-Monitoring ein, das Lücken zwischen semantischem und physischem Modell aufdeckt, um zeitnah auf Anpassungsbedarf reagieren zu können.Integration ins Datenmanagement-Framework sicherstellen
Verknüpfen Sie das Metadaten-Repository mit Ihrem Governance-Tooling und den Data-Pipelines, damit Metadaten-Workflows nahtlos in Service-Management- und Automatisierungsprozesse eingebettet sind.Enablement und Change Management umsetzen
Führen Sie zielgruppenspezifische Trainings für Data Stewards, Entwickler und Fachanwender durch, um den Umgang mit Repository, Ontologie und Governance-Workflows zu schulen. Ergänzen Sie dies um Kommunikationspläne und Stakeholder-Engagement, um Akzeptanz zu fördern und kontinuierliche Verbesserungen sicherzustellen.
- Enterprise Self-Service-Portal einführen
Implementieren Sie eine zentrale Plattform (Data Catalog/Data Mesh) als Single Point of Access für alle Data Products und sichern Sie über eine intuitive Oberfläche sowie standardisierte Prozesse den bereichsübergreifenden Zugriff. - Data-Product-Pool definieren und publizieren
Identifizieren und katalogisieren Sie wiederkehrende Datenservices (z. B. Stammdaten, Sensordaten, KPI-Sets) als eigenständige Data Products. Legen Sie klare Service-Level-Agreements (Verfügbarkeit, Durchsatz, Latenz) fest und veröffentlichen Sie diese im Self-Service-Portal. Nutzen Sie dabei die aus dem Metadatenmanagement entwickelte Taxonomie als Basis. - Zugriffskonzepte und Policy Enforcement automatisieren
Harmonisieren Sie rollenbasierte Zugriffsrechte und definieren Sie gleichzeitig externe „Need to Know“-Regeln für Partner und regulatorische Anforderungen. Setzen Sie automatisierte Gateways ein, die Zugriffsanfragen validieren und freigeben – ganz ohne manuelle Eingriffe. - „Need to Know“ vs. „Need to Share“ klar regeln
Erarbeiten Sie mit Datenlieferanten und -nutzern einen abgestuften Katalog, der interne Sharing-Szenarien („Need to Share“) und externe Freigaben („Need to Know“) klar trennt. Verankern Sie diese Regeln im Governance-Framework und in den Governance-Tools. Verknüpfen Sie Einstufungen semantisch und physisch mit dem Metadaten-Katalog, um Use Case für Use Case dedizierte Pools an „Need to Share“-Daten zu etablieren – effizient und regulatorisch sicher. - Monitoring, Usage Analytics und Auditing etablieren
Richten Sie Dashboards ein, die Nutzungsstatistiken (Wer greift wann auf welche Data Products zu?) visualisieren, und generieren Sie automatisierte Reports für Compliance, Qualitätssicherung und Ressourcenallokation. Definieren Sie Alarme für ungewöhnliche Zugriffsmuster und andere handlungsrelevante Ereignisse. - Change- und Enablement-Maßnahmen durchführen
Schulen Sie Fachbereiche und Partner in der Nutzung des Self-Service-Portals, vermitteln Sie die neuen Sharing-Richtlinien und bieten Sie Hands-on-Workshops an. Steigern Sie Akzeptanz durch regelmäßige Success Stories und Best-Practice-Präsentationen im Governance Council und klären Sie Datenverantwortliche gemeinsam mit Datenschutz- und Risikomanagement über regulatorische Anforderungen und Risiken auf.
- Orchestrierungs-Framework einführen
Evaluieren und implementieren Sie eine zentrale Plattform zur Steuerung aller Batch- und Streaming-Pipelines. Definieren Sie ein wiederverwendbares Architektur-Pattern inklusive Standard-Templates für gängige Datenflüsse. - Infrastructure-as-Code und CI/CD umsetzen
Verankern Sie Pipeline-Definitionen als Code in einem Versions-Repository. Richten Sie automatisierte Tests und Deployment-Pipelines ein, um Änderungen kontrolliert in Entwicklungs-, Test- und Produktionsumgebungen zu übernehmen. - Einheitliche Konnektoren und Datenadapter standardisieren
Verwenden Sie modulare, wiederverwendbare Konnektoren für Quellsysteme und integrieren Sie Batch- und Echtzeit-Anbindungen in einem konsistenten Framework. - Monitoring, Logging und SLA-Reporting etablieren
Implementieren Sie ein zentrales Observability-Dashboard, das Durchsatz-, Latenz- und Fehlerraten aller Pipelines visualisiert. Automatisieren Sie Alerts und SLA-Reports, um Verantwortliche bei Abweichungen sofort zu informieren. - Automatisierte Fehlerbehandlung und Recovery-Workflows
Implementieren Sie Retry-Mechanismen, Dead-Letter-Queues und Backoff-Strategien. Definieren Sie klare Eskalations- und Wiederherstellungsprozesse, die automatisch greifen und Data Stewards bei Bedarf benachrichtigen. - Change Management und Enablement
Schulen Sie Data-Engineering-Teams in den neuen Orchestrierungs- und IaC-Werkzeugen. Pflegen Sie eine zentrale Bibliothek mit Pipeline-Templates, Best Practices und Lessons Learned für schnellen Wissenstransfer und kontinuierliche Verbesserung.
- „Data is Business“ als Grundprinzip etablieren
Etablieren Sie die Datenstrategie als klaren und zentralen Bestandteil des Business. Setzen Sie die Fachabteilungen dediziert in die Führungsrolle in dieser Transformation ein und prägen Sie das Verantwortungsgefühl und Verständnis der Bereiche für ihre Daten. Executive Sponsorship und datengetriebene Zielvorgaben etablieren
Gewinnen Sie C-Level- und Bereichsverantwortliche als aktive Fürsprecher, verankern Sie die Datenstrategie in den übergeordneten Geschäftszielen und kaskadieren Sie die Zielsetzungen in alle Organisationsebenen. Definieren und kommunizieren Sie unternehmensweite KPIs zur Fortschrittsmessung.Datenkompetenz und Data Literacy fördern
Starten Sie maßgeschneiderte Trainingsprogramme für Führungskräfte, Fachbereiche und IT-Teams, um Grundlagenwissen zu Daten, Analysemethoden und Tools zu vermitteln und eine gemeinsame Sprache zu schaffen. Legen Sie den Fokus auf Umsetzungsvorteile im laufenden Arbeitsumfeld.Data Champions und bereichsübergreifende Communities aufbauen
Benennen Sie in jedem Fachbereich Data Champions, die Best Practices teilen, Innovationsimpulse geben und als Brückenbauer zwischen den Abteilungen fungieren. Integrieren Sie IT-Abteilungen als gleichberechtigte Partner in diesen Austausch.Kommunikations-Setup implementieren
Etablieren Sie einen kontinuierlichen Kommunikationsplan mit Townhall-Meetings, Newslettern und Success Stories, um Erfolge, Learnings und Meilensteine transparent darzustellen und die Akzeptanz für Ihr Data Management Framework nachhaltig zu stärken.
- Data Governance Framework in operative Prozesse integrieren
Leiten Sie aus dem Framework konkrete Arbeitsmodelle ab und verankern Sie diese in Ihren (agilen) Entwicklungsprozessen. Verknüpfen Sie dabei Daten- und Informationsarchitektur mit den praktischen Umsetzungsschritten und beziehen Sie alle weiteren Architektur-Ebenen – von Prozessen über Applikationen bis zur Technologie-Bebauung – mit ein. - Enterprise-Architektur-Blueprint etablieren
Richten Sie ein zentrales Architektur-Repository ein, das konzeptionelle Modelle für Daten-, Anwendungs- und Infrastruktur-Schichten enthält. Nutzen Sie dieses „Single Source of Truth“ für alle neuen Data Use Cases, um Wiederverwendbarkeit, Konsistenz und Compliance sicherzustellen. Organisieren Sie die Architektur-Ebenen entweder zentral oder integrieren Sie spezialisierte Tools über geeignete Schnittstellen. - Vorlagen, Checklisten und Best Practices bereitstellen
Erstellen Sie eine Bibliothek mit Methodentemplates und Architektur-Referenzmustern und machen Sie diese allen Teams zugänglich – so verhindern Sie Insellösungen und verkürzen die Time-to-Value neuer Projekte.
Bereit für den nächsten Schritt?
Für den nächsten Schritt bedarf es eines strategischen Ausbaus von Governance‑Framework, Metadaten‑Ontologie, Data‑Ops‑Methodik sowie Führung und Kultur, die datengetriebene Skalierung aktiv vorantreiben.
Stufe 03
Skalieren & Automatisieren
In der dritten Stufe laufen Anwendungsfälle wie Echtzeit-Compliance, Predictive Maintenance oder Live-Personalisierung vollständig automatisiert, hoch skalierbar und KI-gestützt. Orchestrierte Datenpipelines, robuste Steuerungsstrukturen und adaptive Metadaten-Workflows sorgen dafür, dass sich die End-to-End-Prozesse nahtlos an neue regulatorische Anforderungen, technologische Innovationen und wachsende Geschäftsdomänen anpassen.
- Compliance und Regulation
Über orchestrierte Data‑Pipelines werden alle relevanten Kennzahlen – vom Digitalen Product Pass bis zu CSRD‑Metriken – in Echtzeit aggregiert und in zentralen Dashboards für Fachbereiche und Regulatoren bereitgestellt. Datenqualitäts‑ und Datenschutzrichtlinien sind fest in der Governance‑Toolchain verankert, sodass automatisierte Workflows bei Abweichungen unmittelbar Audits und Korrekturmaßnahmen anstoßen. Metadaten‑getriebenen Schema‑Updates können von den Fachstellen nahtlos ergänzt werden, was einen permanenten Verbesserungs‑ und Anpassungsprozess ermöglicht. - Customer Experience und Customer Data Protection
Live‑Personalisierung über alle Kanäle hinweg: Kundenprofile werden in Echtzeit aktualisiert, KI‑Bots spielen kontextgerechte Angebote aus und alle Transaktionen laufen unter feingranularen Consent‑Regeln der Data Governance. Metadaten regeln automatisch die Sichtbarkeit von Attributen, und ein integrierter Privacy‑Engine‑Service sorgt für DSGVO‑konforme Dokumentation. Künftig werden In‑Store‑Analytics und IoT‑Gerätedaten eingebunden und automatisierte Privacy‑Impact‑Assessments gestartet. - Daten als Wissensspeicher
Ein unternehmensweiter Metadaten‑Katalog mit Ontologie und Wissensgraph macht alle Geschäftsobjekte – von Maschinen und Prozessen bis zu Kundenprofilen – per Self‑Service abrufbar. Experten veröffentlichen Data Products mit kontextueller Semantik, die in physische Datenschemata einfließen. Integrierte Governance‑Workflows entwickeln die Ontologie fortlaufend weiter; KI‑gestützte Extraktoren werden außerdem unstrukturierte Quellen wie Dokumente oder E‑Mails anbinden. - KI‑Anwendungen
Sensordaten, Prozess‑ und Servicelogs werden über Streaming‑Services kontinuierlich eingespeist. Semantic‑prompting‑Parameter aus dem Enterprise Knowledge Graph kontextualisieren die Inputs, sodass Verarbeitung und Ausgabe unternehmensspezifisch erfolgen. Retraining‑Zyklen sind etabliert und ein integriertes Model‑Monitoring überwacht Drift sowie Bias. Zukünftig wird die Anbindung externer Benchmark‑Daten die Vorhersagegenauigkeit und Modellrobustheit weiter steigern. - Produktionsdaten & integrierte KI‑Use Cases
Automatisierte Streaming‑Pipelines transportieren Live‑Sensordaten aus allen Standorten und Anlagenvarianten in zentrale Analytics‑ und KI‑Umgebungen. Predictive Maintenance‑Algorithmen, Produktionsplanungsheuristiken und Supply‑Chain‑Steuerung sind in orchestrierten Workflows verknüpft, sodass Wartungsfenster automatisch gebucht und Nachschubprozesse initiiert werden. - Cross Company Collaboration
Mit nahtlos integrierten APIs und einer Data Mesh–Architektur ist das Unternehmen in Datenräumen wie CatenaX voll operational. Zugang und Freigaben laufen automatisiert, Standardformate und Security‑Policies werden metadata‑basiert gewartet. End‑to‑End‑Prozesse wie das Echtzeit‑Tracking von Komponenten über Partnergrenzen hinweg laufen ohne manuelle Zwischenschritte. Künftige Self‑Service‑Onboarding‑Templates ermöglichen das dynamische Hinzufügen neuer Partner. - Operative Effizienz und Automatisierung
Sämtliche Kernprozesse werden per Event‑Streaming in das Process‑Mining‑Framework gespeist. Live‑Analysen decken Abweichungen auf, rule‑basierte Trigger lösen sofort RPA‑Bots oder Mikroservices aus, um Workflow‑Abhängigkeiten zu steuern. Mithilfe von „Process Variants Discovery“ werden fortlaufend neue Automatisierungspotenziale identifiziert, und Domänen wie HR oder Finance werden sukzessive ins zentrale Monitoring eingebunden.
Kick-Start zur Data-Driven Company – Ihre Basis für KI, datengetriebene Use Cases & Wissensmanagement
Verwandeln Sie Rohdaten in greifbare Werte: Mit unserem praxisbewährten Kick-Start-Programm schaffen Sie in wenigen Wochen die Voraussetzungen für eine nachhaltige, datengetriebene Transformation.
- Individueller Strukturrahmen mit integrierter Use-Case-Blaupause
- Rascher Projektstart dank Voranalyse, erprobter Templates und Best Practices
- Einheitlicher Integrationsansatz für Synergien und skalierbare Bausteine
- Punktgenaue Gap-Analyse zur sofortigen Kompetenz- und Ressourcenentwicklung
Nach dem Prinzip „Think big, start small“ setzen wir auf einen bewährten Methodenkoffer und praxisorientiertes Know-how: Gemeinsam erarbeiten wir einen maßgeschneiderten Strukturrahmen, verproben ihn mit einem fokussierten Pilot-Use Case und übertragen die gewonnenen Erkenntnisse auf Ihre strategischen Dateninitiativen. So entsteht ein belastbares Gerüst zur Konzeption und Planung Ihrer wichtigsten Transformationsfelder – effizient, iterativ und wirkungsgarantiert.
Ihr Ansprechpartner

Entdecken Sie auch unsere Data Workshops
Data Role Workshop
Erfahren Sie, wie Ihr Unternehmen in nur wenigen Tagen zu klar definierten Datenrollen, eindeutigen Verantwortlichkeiten und einer belastbaren Data Governance gelangt – praxisnah strukturiert, organisatorisch verankert und als fundierte Entscheidungsbasis für Strategie, Zusammenarbeit und datengetriebene Transformation nutzbar.
Semantic Data Modeling Workshop
Erfahren Sie, wie Ihr Unternehmen in nur einem Tag ein tragfähiges, fachlich sauberes Informationsmodell entwickelt – klar strukturiert, geschäftsorientiert und sofort nutzbar als Grundlage für Analytics, KI und bessere Entscheidungen. Sie gewinnen Transparenz über Datenflüsse, Verantwortlichkeiten und Qualität, bündeln Wissen aus Köpfen in einem wiederverwendbaren Modell und schaffen damit die Basis für skalierbare, verlässliche und beschleunigte datengetriebene Umsetzung.
Data Use Case Workshop
Erfahren Sie, wie Ihr Unternehmen in nur einem Tag die relevantesten Data‑ und KI‑Use Cases identifiziert, deren Nutzen, Machbarkeit und Risiken bewertet und daraus eine klare, priorisierte Roadmap ableitet. Sie erhalten Transparenz über Informationskontexte, Datenqualität und Abhängigkeiten und schaffen eine belastbare Entscheidungsgrundlage, die Strategie, Business und Umsetzung konsequent zusammenführt – für schnellere Ergebnisse statt endloser Diskussionen.
Weiterführende Artikel










Jetzt unverbindliches Erstgespräch vereinbaren
- Zukunftsorientiert: Potenziale gezielt als Wachstumstreiber nutzen
- Maßgeschneidert: Individuelle Lösungen für Ihre spezifischen Herausforderungen
- Erprobt: 20 Jahre Praxis aus erfolgreichen Projekten garantiert Verlässlichkeit
- Umsetzungsstark: Von Konzeption bis zur messbaren Ergebnisrealisierung
- Werteorientiert: Klare Fokussierung auf nachhaltigen Nutzen und echte Wettbewerbsvorteile

TISAX und ISO-Zertifizierung nur für den Standort in München
Ihre Nachricht
Häufig gestellte Fragen an eine Datenstrategie Beratung
Eine Datenstrategie legt fest, wie ein Unternehmen Daten systematisch erfasst, verwaltet und nutzt, um geschäftlichen Mehrwert zu schaffen. Sie definiert Standards für Qualität, Sicherheit und Governance und fördert datenbasierte Entscheidungen. Ziel ist es, Transparenz, Effizienz und Innovation datengetrieben zu unterstützen.
Daten sind eine zentrale Ressource für Wettbewerbsfähigkeit, Innovation und operative Exzellenz. Eine klare Datenstrategie stellt die Basis dar, um Potenziale gezielt zu nutzen und Risiken zu minimieren – besonders in Zeiten von KI, wachsender Datenmengen und regulatorischer Anforderungen.
Die Basis einer Datenstrategie ist die Analyse der vorhandenen Datenlandschaft sowie eine enge Ausrichtung an den Geschäftszielen. Daraus leiten sich klare Ziele, relevante KPIs und geeignete Technologien ab. Erfolgsentscheidend sind eine starke Datenkultur und die kontinuierliche Weiterentwicklung der Strategie.
Die IT schafft die technologische Basis für Datenverfügbarkeit, Skalierbarkeit und Sicherheit. Gemeinsam mit den Fachbereichen sorgt sie dafür, dass Datenlösungen praxisnah und strategiekonform umgesetzt werden.
Eine Datenstrategie-Beratung unterstützt Unternehmen dabei, ihre Daten systematisch nutzbar zu machen – von der Analyse des Ist-Zustands über die Definition strategischer Ziele bis hin zur Entwicklung konkreter Maßnahmen. Sie begleitet die Umsetzung technisch wie organisatorisch und sorgt dafür, dass Datenlösungen auf messbaren Business Value ausgerichtet sind.
Sie soll das Potenzial von Daten gesellschaftlich und wirtschaftlich besser nutzbar machen – durch eine vertrauenswürdige Infrastruktur, hohe Datenschutzstandards und Förderung digitaler Souveränität. Im Fokus stehen der Aufbau von Datenplattformen, Kooperationen mit Wirtschaft und Forschung sowie KI-Anwendungen.